



Next: 3 Ordinal Data Analysis
Up: 2 Continuous Data Analysis
Previous: 1 SAS scripts to
Index
3 Using PRELIS to Summarize Continuous Data
PRELIS was developped by Karl Jöreskog and Dag Sörbom as a preprocessor
for LISREL[].
Here we apply PRELIS to the simulated MZ twin data, and
briefly discuss some of the further features of the software. In practice, data
on MZ and DZ twins may be placed in separate files, often with one or more
lines of data per twin pair![[*]](footnote.png) . It is easy to use PRELIS to generate summary statistics
such as means and covariances for structural equation model fitting.
Suppose that the MZ twin data in Table 2.1 are stored in a file
called
. It is easy to use PRELIS to generate summary statistics
such as means and covariances for structural equation model fitting.
Suppose that the MZ twin data in Table 2.1 are stored in a file
called MZ.RAW in the following way:
3 2
3 3
. .
. .
. .
2 1
1 2
We can use ``free format'' to read these data. Free format means that
there is
at least one space or end-of-line character between consecutive data items.
These data could be entered using any simple text editor. If a
wordprocessor such as Wordperfect or Microsoft Word were used, it would be necessary to save the
file as a DOS or ASCII text file. Next, we would prepare an ASCII file
containing the PRELIS commands to read these data and compute the means and
covariances. We refer to files containing program commands as
`scripts'; the PRELIS script in this case might look like this:
Simple prelis example to compute MZ covariances
DA NI=2 NO=0
LA
Twin1 Twin2
COntinuous Twin1 Twin2
RAw FIle=MZ.RAW
OU SM=MZ.COV MA=CM
The first line is simply a title. PRELIS will treat all lines as part of the
title until a line beginning with DA is encountered. The DAta line
is used to specify basic features of the input (raw) data such as the number of
input variables (NI) and the number of observations (NO).
Here we have
specified the number of observations as zero (NO=0), which asks PRELIS to count the
number of cases for us. The next two lines of the script supply labels
(LA) for the
variables; these are optional but highly recommended when more than a few
variables are to be read. Next, we define the variables Twin1 and Twin2 as
continuous. By default, PRELIS 2 will treat any variable with less than 15
categories as ordinal. Although this is a reasonable statistical approach, it
is not what we want for the purposes of this example. The next line in the
script (beginning RAw) tells PRELIS where to find the data, and the OUtput
line signifies the end of the script, and requests the covariance matrices
(MA=CM) to be saved in the file MZ.COV. This output file is
created by PRELIS -- it is also ASCII format and looks like this:
(6D13.6)
.106667D+01 .800000D+00 .106667D+01
The first line of the file contains a FORTRAN format for reading the data. The
reader is referred to almost any text on FORTRAN, including User's Guides, for
a detailed description of formats. The format used here is D format, for
double precision. The 3 characters after the D give the power of 10 by which
the printed number should be multiplied, so our .106667D+01 is really
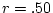 . This number is part of the lower triangle
of the
covariance matrix. Since covariance matrices are always symmetric, only the
lower triangle is needed. The file may in turn be read by Mx for the
purposes of structural equation model fitting using syntax such as
. This number is part of the lower triangle
of the
covariance matrix. Since covariance matrices are always symmetric, only the
lower triangle is needed. The file may in turn be read by Mx for the
purposes of structural equation model fitting using syntax such as
CMatrix File=MZ.COV
within an Mx script -- Mx by default expects only the lower triangle of
covariance matrices to be supplied.
Suppose that, instead of just two variables, we had a data file with 20
variables per subject, with two lines for a twin pair. Also suppose that one
of the variables identifies the zygosity of the pair, we wish to select only
those pairs where zygosity is 1, and we only want the covariance of four of the
variables. We could read these data into PRELIS using a FORTRAN format
statement explicitly given in the PRELIS script. The script might look like
this:
PRELIS script to select MZ's and compute covariances of 4 variables
DA NI=40 NO=0
LA
Zygosity Twin1P1 Twin1P2 Twin2P1 Twin2P2
RA FIle=MZ.RAW FO
(3X,F1.0,2x,F5.0,12X,F5.0/6X,F5.0,12X,F5.0)
SD Zygosity=1
OU SM=MZ.COV MA=CM
Note the FOrtran keyword at the end of the raw data line, indicating that the
next line contains a Fortran format statement.
The SD command selects cases where zygosity is 1, and deletes zygosity from the
list of variables to be analyzed. Note that the FORTRAN format implicitly skips
all the irrelevant variables, retaining only five (as specified by
the F1.0 and F5.0 fields). Although we could have started with a more
complete list of variables, read them in with an appropriate FORMAT, and used
the PRELIS command SD to delete those we did not want, it is more
efficient to save the program the trouble of reading these data by adjusting
our NI and format statement. On the other hand, if the data file is not
large or if a powerful computer is available, it may be better to use SD to
save user time spent modifying the script.
Next: 3 Ordinal Data Analysis
Up: 2 Continuous Data Analysis
Previous: 1 SAS scripts to
Index
Jeff Lessem
2002-03-21