


Next: 1 Calculating Summary Statistics
Up: 2 Data Preparation
Previous: 1 Introduction
Index
2 Continuous Data Analysis
Biometrical analyses of twin data often make use of summary
statistics that reflect differences, or variability, between and
within members of twin pairs. Some early studies used mean squares and
products,
derived from an analysis of variance
[Eaves et al., 1977,Martin and Eaves, 1977,Fulker et al., 1983,Boomsma and Molenaar, 1987,Molenaar and Boomsma, 1987], but work over
the past 15 years
has embraced variance-covariance matrices as the summary statistics of choice.
This approach, often called covariance structure analysis,
provides greater
flexibility in the treatment of some of the processes underlying
individual differences, such as genotype 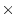 sex or genotype
environment interaction. In addition, variances and covariances are a more
practical data summary for data that include the relatives of
twins, such as parents or spouses [Heath et al., 1985]. Because of the
greater generality afforded by variances and covariances, we
focus on these quantities rather than mean squares.
sex or genotype
environment interaction. In addition, variances and covariances are a more
practical data summary for data that include the relatives of
twins, such as parents or spouses [Heath et al., 1985]. Because of the
greater generality afforded by variances and covariances, we
focus on these quantities rather than mean squares.
Subsections
Jeff Lessem
2002-03-21